

Hacking the Xbox 360 Hypervisor Part 2: The Bad Update Exploit
Welcome to part 2 of the Hacking the Xbox 360 Hypervisor blog series. In this part I’ll cover how I found and exploited bugs in the Xbox 360 hypervisor to get full code execution and create the “Bad Update” exploit. If you haven’t already, I highly recommend you read (or at least skim through) part 1 as this post will reference a lot of the material discussed there.
As I mentioned in part 1, I consider the Xbox 360 hypervisor to be one of the most secure pieces of code Microsoft has ever written, with only one software bug to date that was likely the result of a compiler issue. I spent a lot of time in the past looking for vulnerabilities in the hypervisor but never found anything of significance. Since then, I’ve spent 7 years working as a security engineer professionally and had developed a whole new mindset for how I analyze targets and find bugs. I was very motivated to put my new skills to the test and see if I could finally hack the Xbox 360 hypervisor. This is what I considered “the final boss” of my journey as a game console hacker.
Testing Environment
My goal was to exploit a game save bug I found in Tony Hawk’s American Wasteland to start an exploit chain that would hopefully end with me getting hypervisor mode code execution. My testing environment for doing this research consisted of an already modified Xbox 360 console that had full debugging capabilities. This allowed me to write exploit tests in C code which I could run and debug on the console, while also being able to introspect the internal state of the hypervisor. I wanted to focus my efforts on determining if any bugs I found were actually exploitable, and writing the exploit tests in C code that I could debug was the fastest way to do this. Once I had a viable exploit I could worry about triggering it from the Tony Hawk game save bug.
Analyzing Attack Surface
In part 1 I talked a bit about the system call attack surface the hypervisor exposes to kernel mode. I looked through many of the system calls nearly 15 years ago when I first started researching the console but never found anything noteworthy. However, now that I had a new mindset for bug hunting it was time to look through all of the available attack surface starting fresh. Due to how little attack surface there is in the Xbox 360 hypervisor I decided on “code review” for my method of finding bugs. It didn’t really make sense to try and write a fuzzer or emulation harness and would have been way more work than just doing code review anyway. I say “code review” here because I don’t actually have access to the source code and what I’m really doing is reverse engineering/analyzing the disassembly of the hypervisor binary in IDA.
In my first pass of “code review” I’d be looking for “trivial” bugs, things like out of bounds reads/writes, race conditions/lack of locking, time of check/time of use bugs, integer overflows/underflows, missed validation of parameters, etc. I call these “trivial” because many of these can be exploitable without any additional primitives and don’t require a complex attack scenario.
System Calls
At launch the hypervisor had 65 system calls which increased to 120 by the end of its lifecycle, nearly doubling the amount of attack surface it exposed to kernel mode. The hypervisor system calls can be called by any code in kernel mode at any time and provide a range of functionality to support the console OS. The system call attack surface is very secure and has thorough validation of all parameters, only operates on data in protected memory and performs signature checks on most forms of data that involve parsing logic. While there were a few system calls that had notable or interesting behavior (things like cache flushing primitives, arbitrary writes to unprotected memory, etc.) I didn’t find anything that could be used to try and attack the hypervisor itself.
XeKeysExecute Payloads
There’s a special system call called HvxKeysExecute that’s used for running small pieces of ad-hoc code in hypervisor mode. This system call takes in a XeKeysExecute (XKE) payload which is a small piece of code signed by Microsoft that the hypervisor will load and execute dynamically. These payloads typically perform a single operation like update or validate some encrypted security file or provide a way for Microsoft to ship anti-cheat payloads through Xbox Live. XKE payloads are good attack surface because they perform non-standard ad-hoc operations, typically take in parameters and data from kernel mode to operate on, and typically have no version or runtime checks that prevent you from running them out of band. Put simply: any executable (game, dashboard, or otherwise) can typically run these at any time on any system software version.
These payloads are most commonly used by system update executables to perform additional security operations when updating the console. I leveraged this to my advantage and downloaded around ~85 system update packages I found online to help build a collection of payloads for analysis. After writing some scripts to extract the update files and scan them for XKE payloads I had around 25 XKE payloads for analysis. Unfortunately, I didn’t find any trivial bugs in them. There was one payload that stood out as having some interesting behavior that could be exploitable but required I had a way to attack encrypted memory. Since I didn’t have any way to do this just yet I made note of the payload and moved on.
Findings (none)
I wasn’t hopeful I would find any fruitful results in this first pass and to be honest I would’ve been disappointed if I did. After a few days of code review on the attack surface available I had found nothing notable, which was to be expected. However, this did allow me to learn more about how encrypted and protected memory worked which gave me a few ideas for possible attack vectors. Faced with a lack of attack surface it was time to think outside the box and see if I could “create” more attack surface.
Attacking Encrypted Memory
With no bugs found the next thing I turned to was trying to attack encrypted memory as this would allow me to try and attack the notable XKE payload I found earlier. Since encrypted memory doesn’t have any CRC checksums it can be modified from outside of the hypervisor, but I’d need to find a way to craft the ciphertext for data I wanted to write. Encrypted memory is typically used in a “write-only” fashion by the hypervisor. It’s clear Microsoft was aware it could be modified by kernel mode and therefore almost never read back from encrypted memory and operate on it. However, this notable XKE payload was doing just that and seemed like it could lead to some exploitable bugs in hypervisor mode.
Attacking this notable XKE payload was going to be difficult so I decided it would be best to first find an easier target and prove I could successfully attack encrypted memory without worrying about extraneous variables. There are only a few things that are stored in encrypted memory, mainly all kernel mode code, as well as some security related data that’s shared between the hypervisor and kernel (revocation lists, kernel mode RNG state, etc.). Attacking the encrypted memory for some kernel mode code seemed like a good test candidate as I could overwrite it with my own assembly code to do something like change the console’s LED colors, thus proving the attack worked.
Encrypted Memory Allocations
Both the protected and encrypted memory pathways perform encryption by mixing together a 10-bit whitening value, a per-boot per-pathway encryption key, and the address of cache line containing the memory being accessed. This prevents attackers from trying ciphertext manipulation attacks such:
- Using ciphertext from address A at address B where A != B.
- Using ciphertext from the protected pathway with the encrypted pathway (or vice versa).
- Using ciphertext across resets/reboots of the CPU.
The hypervisor manages a table of values that I’ll refer to as the “page whitening table” which tracks encrypted pages of memory (on a 64KB granularity) and what whitening values have already been used on those pages. Every time the hypervisor allocates a page of memory for the encrypted pathway it’ll call a function I’ve named “HvpSetPageWhiteningBits”. This function will check the page whitening table to determine the next whitening value to use for the page. When the console boots, all entries are initialized to 0 and each time a page of encrypted memory is allocated the whitening value will be incremented by 1 until it reaches 1024 (the point at which a 10-bit integer would overflow). At this point an overflow bit will be set which indicates all possible whitening values have been used exactly once. Any allocation of the page thereafter will use a randomly generated number for the whitening value. The pseudo code for this function can be seen below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
struct PAGE_WHITENING_TABLE_ENTRY { WORD WhiteningValue : 10; WORD WhiteningOverflow : 1; WORD Valid : 1; }; DWORD HvpSetPageWhiteningBits(PAGE_WHITENING_TABLE_ENTRY* pPageAllocationTablePtr, DWORD pageNumber) { WORD whiteningValue = 0; // Get the whitening entry for the page. PAGE_WHITENING_TABLE_ENTRY* pPageEntry = &pPageWhiteningTablePtr[pageNumber]; // Check if the whitening values have all been used at least once. if (pPageEntry->WhiteningOverflow == 0) { // Use the next whitening value until overflow is triggered. whiteningValue = pPageEntry->WhiteningBits++; } else { // Randomize the whitening value. XeCryptRandom(&whiteningValue, sizeof(whiteningValue)); } // Isolate and return the 10-bit whitening value. return whiteningValue & 0x3FF; } |
The purpose of this function is to introduce entropy into the encryption used across allocations of the same page of memory. Each time the page is allocated the ciphertext will change even if the plaintext data doesn’t.
A Hypothetical Attack Scenario
While it may seem like all the per-boot/per-pathway/per-page encryption feeds make it difficult to perform ciphertext attacks this is actually quite easy to defeat. Sure we could just change the ciphertext arbitrarily and the resulting plaintext would change as well. But this doesn’t give us any control over what the resulting plaintext data will be and trying to brute force out even 16 bytes of random data that happens to give us some 16 bytes of plaintext data we want isn’t really feasible.
However, say we have some way to get the ciphertext for arbitrary plaintext data even though we don’t know what whitening value was used to create the ciphertext. For any given address there’s only 1024 possible ciphertext values for any constant plaintext data because the only entropy into the memory encryption will be the 10-bit whitening value. 10-bits is a very small search space and could easily be brute forced through in seconds to minutes if we had some primitive to cycle the whitening value and encrypt some known plaintext data.
Consider the following attack scenario:
- Choose some 64KB page of memory at address A such that A falls within the executable region for some executable file (could be a game executable or dll).
- Get the ciphertext for all possible whitening values for the plaintext data we want to write into memory at address A (this would be our kernel mode shell code). There will be exactly 1024 different ciphertext values.
- Load a game executable or dll into memory (a dll is easier because it can be loaded in a suspended state).
- Loop for 1024 times and perform the following:

The only missing primitive here is a way to generate ciphertext for some arbitrary plaintext data.
Crafting Ciphertext
The primary source of ciphertext for the encrypted pathway is kernel mode code which must be RSA signed by Microsoft. However, tracing all the references to the HvpSetPageWhiteningBits function I found another code path that would work in my favor. The hypervisor implements three system calls that can be used to reserve, encrypt, and release an allocation in encrypted memory at an arbitrary address called HvxEncryptedReserveAllocation, HvxEncryptedEncryptAllocation, and HvxEncryptedReleaseAllocation.
The hypervisor enforces that all executable code is encrypted at runtime and the only memory that’s not encrypted is kernel mode data. This is mostly because data allocations may be used with external devices such as the GPU, southbridge, audio encoder, etc. which have no ability to perform decryption on the data. However, Microsoft wanted to give developers the ability to store data in encrypted memory and created the HvxEncrypted* API set. I’m not entirely sure what the attack scenario would be where one would want to use these APIs, presumably to hide some game data (cryptographic keys maybe?) at runtime from anyone who could dump the contents of RAM from outside the CPU. I can’t really think of any data that would justify the need for these APIs and I honestly don’t know if any game ever used them, but they certainly came in handy for exploitation.
The HvxEncrypted* APIs are pretty simple to use, you start by making a physical memory allocation using the unprotected pathway at the physical memory location you want to generate ciphertext for. Next you pass this address to HvxEncryptedReserveAllocation which marks the pages as in-use, followed by a call to HvxEncryptedEncryptAllocation which sets the page whitening bits and flushes CPU cache. At this point you now have two “views” of the same physical memory location, one through the unprotected pathway using the physical memory allocation address, and one through the encrypted pathway using a virtual address mapped by HvxEncryptedReserveAllocation.
Using these APIs we can craft the ciphertext for arbitrary data by simply writing our plaintext data using the encrypted address, flushing CPU cache, and reading back from the unprotected address. We won’t know what whitening value was used for the encryption but that doesn’t matter. We can simply generate the ciphertext for the data we plan to overwrite and use it as an indicator to know when the whitening value currently in use matches the whitening value used to generate our malicious ciphertext. I’ll hereby refer to this indicator data as our “oracle” data (not to be confused with an oracle machine) as it’s essentially guiding us to finding a whitening value collision.
Overwriting Read-Only Memory
The memory we want to overwrite with our malicious ciphertext is executable code which is marked read-only in kernel mode, so we’ll need to find a way to work around this. There are a couple different techniques I’ve used to overwrite arbitrary memory while ignoring page permissions:
- Southbridge DMA operations
- GPU shaders
- Hypervisor APIs
I’ll cover each of these techniques in-depth in part 3, but for now I’m going to focus on the hypervisor APIs technique as this is what I used for the exploit.
Hypervisor Key Storage
When running in hypervisor mode all memory is considered read-write-execute. If you can find one or more APIs that work as a “read from address A write to address B” primitive you can have the hypervisor do the memcpy operation for you. There are a few places where the hypervisor will perform reads and writes to memory addresses provided by kernel mode using the unprotected pathway. However, I only found two particular APIs that would actually work for a viable memcpy operation: HvxKeysExGetKey and HvxKeysExSetKey.
These two APIs are used to get and set keys in the extended key store that the hypervisor manages. Almost all of the keys in the normal and extended key stores are not accessible to kernel mode and the ones that are accessible are typically read-only. However, the extended key store has a couple keys that are both accessible and writable from kernel mode. I’m not sure what the key slots are supposed to be used for (perhaps IP-TV keys/certificates) but the slot is writable and that’s all that matters.
By calling HvxKeysExSetKey we can store the data we want to write into the extended key store, and call HvxKeysExGetKey to retrieve it. When the retrieval happens the hypervisor will write the key value to the memory address provided by kernel mode using the unprotected pathway. As long as the memory address is outside of the hypervisor address space it’ll write to any memory location you specify. By putting these two APIs into a loop you can create an arbitrary memcpy primitive:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
void MemcpyCipherText(ULONG DstPhys, ULONG SrcPhys, ULONG size) { while (size > 0) { // Setup next block size. ULONG copySize = min(size, 2048); *(ULONG*)pSizeScratch = copySize; // Store the next block to the key store and read it back to the target address. ULONG result = HvxKeysExSetKey(0x102, SrcPhys, copySize); result = HvxKeysExGetKey(0x102, DstPhys, SizeScratchPhysAddr); SrcPhys += copySize; DstPhys += copySize; size -= copySize; } } |
Getting Kernel Mode Code Execution
Now that we have a way to generate ciphertext for arbitrary data and write it to read-only memory it’s time to put everything together and get some arbitrary kernel mode code execution. Since I was testing this on an already hacked console I was able to write the poc for this in C code which I’ve included below. The steps I used for this attack are slightly different than the ones I outlined above but ultimately arrives at the same result.
First we’ll need an executable file we can load and unload dynamically. I chose to use the boot animation dll because it’s stored in system flash (so it exists on every console), can be loaded in a suspended state, and doesn’t terminate the executable that’s currently running. Then I chose the address of some executable code in the dll, 0x98030000, to overwrite with my shell code. The address of any 64KB page of executable code will work.
Getting the Oracle Data
Next we’ll need to get some 16 bytes of plaintext data from the boot animation at the chosen target address (0x98030000), which we’ll use to create our oracle ciphertext data. We’ll also get the physical memory address our target address maps to which we’ll need later on.
|
1 2 3 4 5 6 7 8 9 10 11 |
// Load the boot animation so we can get the physical address of the last code segment. DWORD result = XexLoadImage("Flash:\\bootanim.xex", 0x40000009, 0, &hBootAnim); // Get the physical address of the last code segment. DWORD codePhysAddr = MmGetPhysicalAddress((void*)0x98030000); // Copy the data at this address to use as our whitening oracle. memcpy(abOracleData, (void*)0x98030000, 16); // Unload the boot animation so we can reclaim the memory. result = XexUnloadImage(hBootAnim); |
Generating Our Ciphertext
Next we loop 1024 times and allocate encrypted memory at the chosen target address. This will exhaust the whitening values for the chosen 64KB page and cause the overflow bit to get set such that each subsequent allocation of the page will use a random whitening value. For each iteration we’ll have two addresses to the same physical memory location, an unprotected address which just fetches whatever data is in RAM, and an encrypted address which will encrypt/decrypt data from RAM on access.
After ~50% of the search space has been used (so around i=512) we’ll write the plaintext oracle data to the encrypted address and read back the corresponding ciphertext from the unprotected address. We’ll do the same operation again for the shell code we want to write to memory and capture the corresponding ciphertext. We now have the ciphertext for the oracle data, and the ciphertext for our shell code at virtual address 0x98030000 for some unknown whitening value (presumably it’s 513 but it doesn’t really matter).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
bool GetPayloadCipherText(DWORD TargetPhysicalAddr) { // Arbitrary virtual address that will get mapped through the encrypted pathway to TargetPhysicalAddr. BYTE *pEncryptedAddress = (BYTE*)0x8D000000; // Allocate physical memory (through the unprotected pathway) for the target address we want to encrypt data at. BYTE* pUnprotectedAddress = (BYTE*)XPhysicalAlloc(0x10000, (ULONG_PTR)TargetPhysicalAddr, 0x10000, PAGE_READWRITE | MEM_LARGE_PAGES); // Loop and exhaust all possible whitening values for the memory address. for (int i = 0; i < 1024; i++) { // Allocate encrypted memory. DWORD result = HvxEncryptedReserveAllocation((DWORD)pEncryptedAddress, TargetPhysicalAddr, 0x10000); result = HvxEncryptedEncryptAllocation((DWORD)pEncryptedAddress); // Wait until we exhaust ~50% of the whitening space before capturing cipher text. if (i == 1024 / 2) { // Pass 1: copy the oracle data that will be loaded at this address when bootanim.xex is loaded. memcpy(pEncryptedAddress, abOracleData, 16); // Flush cache and read back ciphertext. KeFlushCacheRange((BYTE*)pEncryptedAddress, 0x80); KeFlushCacheRange(pUnprotectedAddress, 0x80); memcpy(pPayloadCipherText, pUnprotectedAddress, 16); // Pass 2: copy our shell code to the target address we want to overwrite. memset(pEncryptedAddress, 0x41, 0x10000); ReadFile("game:\\shell_code.bin", pEncryptedAddress, 0, 0x10000); // Flush cache and read back ciphertext. KeFlushCacheRange((BYTE*)pEncryptedAddress, 0x10000); KeFlushCacheRange(pUnprotectedAddress, 0x10000); memcpy(pPayloadCipherText + 0x80, pUnprotectedAddress, 0x10000); } // Free the encrypted allocation. result = HvxEncryptedReleaseAllocation((DWORD)pEncryptedAddress); } XPhysicalFree(pUnprotectedAddress); return true; } // Allocate physical memory for the shell code cipher text. pPayloadCipherText = (BYTE*)XPhysicalAlloc(0x10080, MAXULONG_PTR, 0x80, PAGE_READWRITE | MEM_LARGE_PAGES); // Get the physical address of the shell code cipher text buffer. PayloadCipherTextPhysAddr = MmGetPhysicalAddress(pPayloadCipherText); // Find the cipher text for the data we want to overwrite. GetPayloadCipherText(codePhysAddr); |
Finding a Whitening Value Collision
Finally, in an infinite loop we’ll load the boot animation dll and check the ciphertext for our chosen target address 0x98030000. If it matches our oracle ciphertext we know the 64KB page was encrypted using the same whitening value that was used to generate our malicious ciphertext, and we can now write the ciphertext for our shell code to memory. If the oracle data doesn’t match it means a different whitening value was used and we’ll unload the boot animation dll and try again. Once we get a hit we can use the hypervisor extended key store memcpy technique to copy the ciphertext for our shell code to the 64KB executable page which is marked read-only. Then we just jump to the address 0x98030000 and our shell code will execute.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
// Loop and load the boot animation until we find the correct whitening bits. DWORD count = 0; while (true) { // Load the boot animation. result = XexLoadImage("Flash:\\bootanim.xex", 0x40000009, 0, &hBootAnim); // Get the cipher text for the target address. MemcpyCipherText(PayloadCipherTextPhysAddr + 16, codePhysAddr, 16); KeFlushCacheRange(pPayloadCipherText, 0x80); // Check if the ciphertext in memory matches the oracle ciphertext we generated earlier. if (memcmp(pPayloadCipherText, pPayloadCipherText + 16, 16) == 0) { // Overwrite the boot animation code with our shell code ciphertext and flush cache. MemcpyCipherText(codePhysAddr, PayloadCipherTextPhysAddr + 0x80, 0x10000); KeFlushCacheRange((BYTE*)0x98030000, 0x10000); HvxFlushDCacheRange((BYTE*)codePhysAddr, 0x10000); // Call our payload. ULONG (__stdcall *pPayloadFunc)() = (ULONG(__stdcall*)())0x98030000; result = pPayloadFunc(); } // Unload the boot animation. result = XexUnloadImage(hBootAnim); count++; } |
With everything in place I wrote a small piece of assembly code that would set the console’s ring of light to full orange to know when it executed. I ran the exploit and after 30 seconds to a minute it was able to find a whitening value collision and my assembly code ran. I captured a view of the code from a debugger which you can see here:
Now that I had a way to attack encrypted memory it was time to loop back to the notable XKE payload and see if attacking it was feasible.
The Bootloader Update Payload
This notable XKE payload that I’ll refer to as the “bootloader update payload” is used during system updates when the 2nd stage bootloader (2bl) needs to be updated. The reason this payload is interesting is because it reads in data from kernel mode and performs LZX decompression on it. The decompression process requires a scratch buffer to store the LZX decoder context structure which contains various pointers that the hypervisor will use when decompressing data. This scratch buffer is provided by kernel mode and relocated to encrypted memory, which means it doesn’t have any integrity checks and we can attack it from kernel mode asynchronously.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
typedef struct { /* pointer to beginning of window buffer */ byte* dec_mem_window; ... /* input (compressed) data pointers */ byte* dec_input_curpos; byte* dec_end_input_pos; /* output (uncompressed) data pointer */ byte* dec_output_buffer; ... /* memory allocation functions */ PFNALLOC dec_malloc; PFNFREE dec_free; long* dec_memory; ... } t_decoder_context; |
Looking at the decoder context structure there’s a couple juicy pointers we could try and attack. The dec_malloc and dec_free pointers are function pointers so overwriting these would result in the hypervisor jumping directly to some shell code we control. The dec_output_buffer pointer contains the address where decompressed data should be written to, so overwriting this pointer would result in data being written to any real mode address we choose (such as hypervisor code or data). All we need to do is generate the ciphertext for the address we want to write into the decoder context structure and the hypervisor will gladly use any real mode address we put there, whether it points to protected, encrypted, or unprotected memory. So why would Microsoft store this data in encrypted memory and not protected memory if they knew it could be modified asynchronously by kernel mode?
Analyzing the Payload
When the system update process is running and the 2nd stage bootloader needs to be updated, the updater application can have the hypervisor run this XKE payload and it’ll build an updated boot chain for the console in memory. The way this is supposed to work is kernel mode creates one large memory allocation in unprotected memory (around 700-800 KB) that gets divided up into different regions. These regions include a header, update data, decompressed bootloader data, LZX scratch buffer, and a region for the newly updated boot chain.
When the payload starts running it’ll relocate these regions in-place to either encrypted or protected memory depending on the size of the region. The header and compressed update data are relocated to protected memory as both regions are smaller than 64KB, and the decompressed bootloader data, LZX scratch buffer, and updated boot chain are relocated to encrypted memory as each region is too large to fit into a single slot of protected memory (64KB). Technically speaking each region could fit into protected memory if it spanned more than one slot but because a change in slot means a change in the upper 32-bits of a real mode address you’d have to handle this address break in code. You can’t just roll off the end of the 64KB page for slot N and into slot N+1 as even though the memory may be physically contiguous the addresses for each slot are not.
Once the memory is relocated the payload will process the update data which is a compressed, encrypted, RSA signed blob that contains every possible 2nd stage bootloader for all the different hardware revisions of the console. The payload will first verify the RSA signature (that only Microsoft can sign) is valid, then decrypt the data, and then decompress it into the decompressed data region. Next the payload will scan a lookup table in the header of the compressed blob that contains a listing of every bootloader in the blob, what CPU, GPU, and HANA chip they match to, and try to match one of the entries to the console. If a match is found and the blob contains an updated 2nd stage bootloader for the console, the payload will craft a new boot chain and store it in the final region of the data buffer.
The size of the LZX scratch buffer is calculated as sizeof(LZX_DECODER_CTX) + 2 * window_size, where window_size is the block size of data to be compressed. In other words, the input data is processed in blocks of window_size bytes and compressed. To decompress a block you’ll need a buffer of window_size bytes to hold the decompressed data. In the case of this payload the window size chosen was 0x8000 bytes (32KB), thus the size of the scratch buffer is sizeof(LZX_DECODER_CTX) + 0x10000 and won’t fit into a single slot of protected memory. Had the window size been slightly smaller the scratch buffer would have been able to fit into protected memory. Fortunately for us this works to our advantage because we can attack the encrypted memory for the scratch buffer using the techniques discussed earlier.
Attacking LZX: Attempt 1
In order to attack one of the pointers in the LZX decoder context structure we’ll need the ciphertext for some oracle data to check for a whitening value collision, and the ciphertext for the malicious pointer we want to write into the structure. Using the technique described above the attack would look something like this:
- Obtain the ciphertext for the oracle data and malicious pointer we want to write. For this attack we’ll target the
dec_mallocfunction pointer in the LZX decoder structure. The pointer should be a real mode address that points to some shell code we setup in unprotected memory. - Create two threads:
- Once a whitening collision is observed, thread B will overwrite the
dec_mallocpointer in the LZX decoder structure with the pre-computed ciphertext for our malicious pointer (which points to our shell code). - If we win the race between thread B overwriting the pointer and thread A using the pointer from hypervisor mode, then the hypervisor should jump to our shell code and we’ll get full hypervisor code execution.
For the oracle data I chose to use the ciphertext for the first 16 bytes of LZX decoder structure with values of all 00s. When the payload does the in-place relocation of the LZX scratch buffer it’ll zero-initialize it afterwards. By capturing the ciphertext for 16 bytes of 00s at the same address I can use the zero-initialization of the scratch buffer as a start indicator to know when to hammer the decoder structure with the ciphertext for our malicious function pointer. This is the earliest point in time we can detect a whitening value collision and we’re gonna need as much time as we can get to win the race condition.
Cache Rules Everything Around Me
Unfortunately attacking the dec_malloc pointer isn’t feasible and the reason is that the CPU L2 cache is just too big for the data containing the decoder structure to age out of cache in the time frame we need. When the XKE payload goes to decompress the input data it’ll call LDICreateDecompression which takes in either two function pointers (one for dec_malloc and one for dec_free) or a pointer to a pre-allocated scratch buffer. In the case of this payload the function pointers are always null and a pointer to the LZX scratch buffer region is provided instead. Regardless of which you provide, the dec_malloc pointer will always be set to the value provided in the function arguments.
Immediately after the dec_malloc function pointer is set to NULL LDICreateDecompression calls sub_2668 which will initialize some more of the decoder structure and then try to use the dec_malloc pointer if it’s non-NULL.
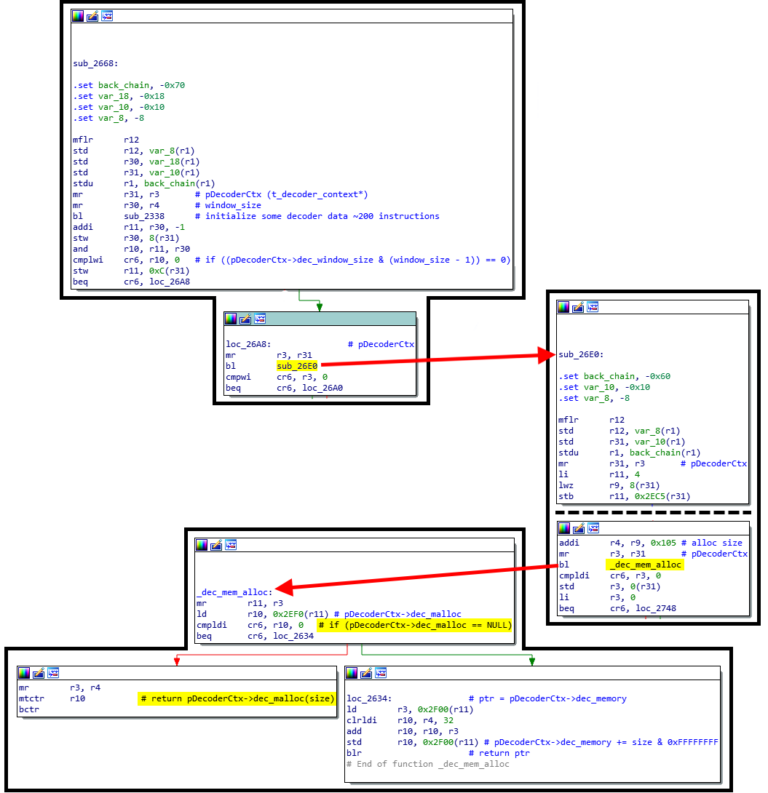
This means we need our malicious ciphertext to be committed to memory by thread B before it’s accessed in _dec_mem_alloc, AND we need the cache line containing the dec_malloc pointer to either age out or be evicted from L2 cache of thread A. Unfortunately, there’s less than 300 instructions between these two operations and the L2 cache is too large for the data to age out or be evicted in this time frame. It’s also not possible to attack the dec_free pointer because the decompression routine never calls LDIDestroyDecompression so the dec_free pointer will never be checked and called. There are some additional things I did to try and put pressure on the CPU L2 cache which I’ll dig into in part 3, but as it stands attacking the dec_malloc/dec_free pointers is a no-go.
Attacking LZX: Attempt 2
Next attempt was trying to attack the dec_output_buffer pointer. When the decompression routine is run the compressed input buffer is decompressed in blocks. Each block will result in a call to LDIDecompress which decompresses the block and copies the decompressed data to the output buffer specified by the dec_output_buffer pointer. The goal for this attack was to successfully overwrite the dec_output_buffer pointer and get the decompressed data copied an address we specify.
This attempt would work mostly the same as the previous attempt except I’d be hammering the dec_output_buffer pointer to point into the last segment of the hypervisor. This particular area doesn’t contain any important code or data so I can freely trash it and observe the ciphertext for it from kernel mode without impacting stability of the hypervisor. Once the ciphertext changes I’ll know I won the race and got the XKE payload to use my malicious dec_output_buffer pointer to overwrite part of the hypervisor. This attack wouldn’t get me hypervisor code execution directly but instead I’d get a write to an arbitrary real mode address from hypervisor context. I’d need to find a way to turn this write into code execution but first I needed to prove the attack worked and that I wouldn’t be blocked by CPU L2 cache.
Since I was focused on determining if the attack was possible and doing all my testing on a console that was already hacked, I decided to modify the XKE payload and make a slight change that would improve my odds of winning the race condition. Each time the XKE payload runs it’ll use a random whitening value for the in-place memory relocation of the LZX scratch buffer. I modified the payload to instead use a constant value of 0x111. This would allow me to skip checking for a whitening value collision and just hammer the ciphertext for the dec_output_buffer pointer continuously in a loop. If the poc worked and the attack was possible then I could worry about winning the race condition later on.
After deploying the poc and modified XKE payload to my hacked console I let it run and got the debug spew that the race condition had been won. The ciphertext for the last segment of the hypervisor had changed which meant this attack was (most likely) feasible. At the very least I had somewhat of an arbitrary write primitive from hypervisor context and now I needed to find a way to turn it into code execution.
Ignoring that I still needed to win the race condition without my static whitening value patch in place, the write primitive I now have is hardly ideal. Every time the write primitive is triggered it’s going to write 0x8000 bytes of data (the size of the block after being decompressed) that I don’t control the contents of. I made a couple attempts to try and get control of the decompressed data before it gets copied to the dec_output_buffer pointer but had no luck in doing so. In most cases it would cause the console to hang or the LDIDecompress function to fail and return early without copying any data. This was a really crappy write primitive but I knew I’d probably never find another one and this could be the only bug I ever end up finding on the console. I accepted the challenge and decided I had to find a way to make it work.
Failure Is Not An Option
The next step is to turn this 0x8000 byte write primitive into something useful. My first train of thought was to use it to perform some memory corruption on other hypervisor data that I could turn into code execution or a more controlled write primitive. I began looking through the data segment of the hypervisor for anything that could be interesting to corrupt such as pointers to other code/data, RSA public keys for code authentication, or internal data structures used by the hypervisor. I found a number of interesting targets and even found some side channels I could use to figure out exactly what data was written to memory. But as I started to conceptualize various attack vectors I quickly realized this wasn’t going to work.
All of the interesting bits of data I was trying to attack were sitting in a minefield of spinlocks the hypervisor uses for acquiring thread safe access to data. My plan of attack depended on specific values within the decompressed data overwriting specific variables in the hypervisor data segment. If I overwrote a spinlock with a non-zero value the hypervisor would never be able to acquire it again, and trying to acquire it would result in that thread getting stuck indefinitely in the spinlock. Some of the spinlocks didn’t matter since they were for functionality that wasn’t important. However, the spinlock that was sitting after all of the interesting data I had found was the spinlock for running XKE payloads. If I overwrote that spinlock I’d never be able to run another XKE payload and I’d basically be locked out from running the write primitive again.
All of the variables I was targeting depended on winning the race condition on a specific block of data. This meant I would need to run the write primitive multiple times until the right block was written, and if I could only run the write primitive once before being locked out then this wasn’t going to work. I tried to find some other variables I could attack with a single write from any decompressed block but I had no such luck in finding any. I spent a few days digging through the data segment over and over but kept coming to the same conclusion: I can’t overwrite anything in the hypervisor data segment that will work to my advantage.
Thinking Outside the Box
After scoping out several other pieces of hypervisor data in different locations with no success I decided to think outside of the box. The data being decompressed was bootloader code (i.e. valid PPC instructions), so I could in theory execute it if I overwrite some other hypervisor code such as a system call function. But I didn’t have any way to determine which block of decompressed bootloader code was written when I won the race condition. However, side channels come in all shapes and sizes. I realized that all of the decompressed blocks had the same size except for the last block. If I observed the ciphertext for the hypervisor code I overwrite I could determine when I won the race on the last block by seeing that the ciphertext changed for less than 0x8000 bytes. Simply observe at two locations such that the second location is greater than the size of the last block but less than 0x8000.
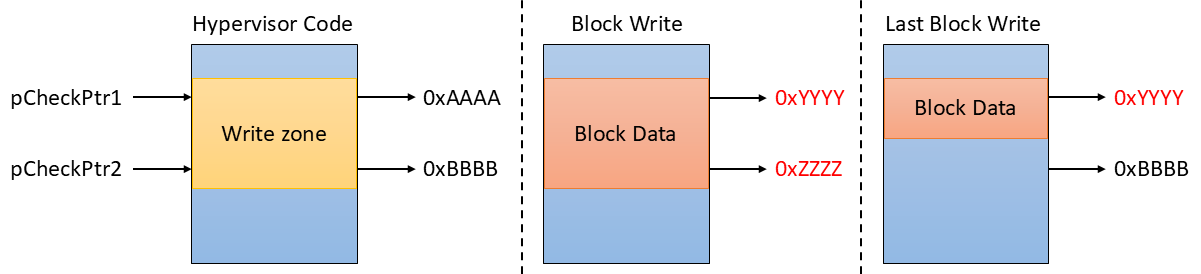
Now that I had a side channel to determine when the last block was written I needed to find some convenient instructions in this block that I could utilize. The idea is to overwrite some hypervisor code such that the first instructions for some hypervisor function get overwritten with some convenient instruction sequence I find in the bootloader data. To make it more complicated the only segment of hypervisor code I could overwrite was the last segment because it’s the only segment that doesn’t contain code for system critical functions which could cause the console to crash if corrupted. Most of this code was for things like IP-TV decryption and DVD drive anti-piracy routines, things that aren’t going to get executed in the background while the system is running.
On top of that only about 12% (or less than 0x2000 bytes) of the last hypervisor segment is code, the rest is just unused. This means any convenient instruction sequence I found in the decompressed bootloader data had to be in the first ~0x2000 bytes or I wouldn’t be able to position it such that it could overwrite the function in the hypervisor segment. The odds weren’t looking good but I began searching through the bootloader code in IDA looking for any instruction sequence I could use. After searching for a bit I found an instruction sequence that was exactly what I was looking for and at an offset that would work:

This instruction sequence will store the bottom byte of r4 to the memory location pointed to by r6+2 and then return. Simply put these two instructions will act as a fully controlled single byte arbitrary write. As an added bonus it has a low offset which makes placing this instruction sequence over some useless system call function in the last hypervisor segment easy. With this final piece of the puzzle I should now be able to write a full exploit chain to get hypervisor code execution.
Getting Hypervisor Code Execution
There are many steps in this exploit chain but the flow will go something like this:
- Obtain the ciphertext for the oracle data and malicious pointer we want to write over the
dec_output_bufferpointer. The malicious pointer will point into the last segment of the hypervisor such that the offset of the stb/blr instruction sequence (0xFA8) in the last block of bootloader data will fall at the start of a system call. I choseHvxFlushUserModeTbbecause it’s the last system call in the segment. - Create two threads:
- Once a whitening collision is hit thread B will overwrite the
dec_output_bufferpointer in the LZX decoder structure with the ciphertext for our malicious pointer. - We’ll know if the race was won because we can observe the ciphertext for the last segment of the hypervisor and see that it changed after the XKE payload was run. By observing the ciphertext in two locations we can determine if less than 0x8000 bytes of data was written which indicates the last block was written.
- Once the race has been won on the last block the instructions for the
HvxFlushUserModeTbsystem call will be replaced with the stb/blr instruction pair. We can now execute this system call from kernel mode and use it as an arbitrary write primitive. - Using the
HvxFlushUserModeTbwrite primitive overwrite an entry in the system call dispatch table to point to an instruction sequence that will get us code execution. For this I chose an instruction sequence that will jump to the address in r4, and overwrote the system call entry forHvxPostOutput. - Set r4 to point to some shell code we create and call
HvxPostOutputfrom kernel mode which will cause the hypervisor to jump to r4 and execute our code. For testing I wrote some assembly code to set the console’s ring of light to full orange and return the value 0x41414141.
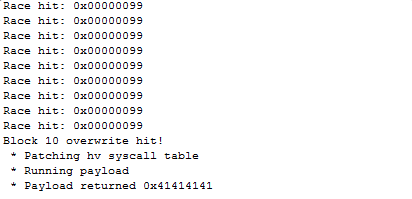
After coding this up and deploying it to my hacked console I let the exploit run. After a minute or two I got the debug spew that the race had been won on the last block and the exploit ran. I could see the console’s ring of light was lit full orange and the shell code returned 0x41414141 back to kernel mode.
At this point I should be good to go, just port this over to work on a non-hacked console and we’re done, hypervisor hacked, right? There’s one thing I forgot when running the last few poc’s and that was the patch I made to the XKE payload to use a static whitening value. I kept this patch in to test the poc with the best possible conditions for winning the race, which is why the exploit triggered in 1-2 minutes. Once I remove this patch the payload will use a random whitening value every time it runs. This means not only do we have to wait for a whitening value collision but we also have to win the race condition which we’re going to fail at many times.
After I removed the patch and reran the exploit I wasn’t even getting debug spew that the race condition was being won for any block, even after 30 minutes there was still nothing. It was starting to seem like this attack wasn’t going to work but I wasn’t ready to give up yet.
Introducing Thread Feng Shui
To try and get a better idea of what was going on I wrote some code/patches to record timestamps for each thread as the XKE payload was running. This gave me timestamps in microseconds for when the XKE payload relocated the LZX scratch buffer to encrypted memory, when it started to decompress each block of input data, and when the attack thread would start/stop hammering the LZX decoder structure. From the timing data I was able to see that by the time the attack thread was able to observe the whitening value collision the payload thread had already decompressed most of the input data. Which meant that by the time the attack thread got the malicious ciphertext flushed to RAM the XKE payload was already done running.

When you create a software thread on the Xbox 360 you can specify which physical hardware thread you want it to run on. I speculated that what hw thread I ran the software threads on actually mattered, and that perhaps the distance to the FSB/L2 cache or inner logic of the L2 crossbar made a difference in how fast the operations completed. To test this I tried a number of different configurations of placing the software threads on different hardware threads and eventually found a configuration that allowed me to win the race condition. I suspected that putting the payload thread as far away from the FSB/L2 cache as possible and the attack thread as close as possible would have had the best results, however, this wasn’t the case.
The configuration with the best results was running the attack thread on hw thread 0 and the payload thread on hw thread 1. It seemed like scheduling them on different CPU cores actually hurt the odds of winning the race condition, and they had to be on the same core. Core 0 also had the best results compared to putting both threads on core 1 or 2. I know basically nothing about how CPUs work at a hardware level, or the inner workings of L1/2 cache and memory transactions. But what I suspect is happening is that each CPU core has its own load/store queues for performing memory transactions. Putting both threads on the same CPU core causes the memory transactions to be queued onto the L2 crossbar together when they would otherwise be queued separately if run on different cores. Put simply, running on the same core batches the loads/stores from both threads when they would otherwise be performed individually, and this significantly reduces the transaction times.
Abusing the CPU for Fun and Profit Cache
Now that I was able to win the race condition with an unmodified version of the XKE payload I at least knew the attack was theoretically possible. However, the rate at which the race condition was being won was abysmal, and it appeared that the race was only being won during the first half of the decompression process. This meant there was a slim chance of winning the race when the last block was being decompressed. Starting with the race condition success rate I knew this was largely due to how big the L2 cache was. Because the payload thread was more likely to fetch data from cache instead of RAM it meant more missed opportunities for it to fetch my malicious ciphertext from RAM. So if I could find a way to thrash L2 cache the race condition success rate should improve.
The Xbox 360 CPU has a 1MB, 8 way associative L2 cache, meaning each of the 8 pathways can map to 128KB of cache space. One of the interesting features of the Xbox 360 is that you can lock access to sections of L2 cache (as well as the pathways) and map it to a virtual address that the GPU can access. Yes, the GPU can read directly from the CPU’s L2 cache. The idea is that instead of having the CPU write data to RAM and then the GPU read it, you can put the data in L2 cache and have the GPU read it directly. This reduces the number of memory transactions from 2 to 1. There are some other performance benefits to this feature, but what it means for us is we have a way to reduce the amount of L2 cache the CPU can use. After figuring out how to use the XLockL2 kernel API I was able to write the following helper function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
void LockAndThrashL2(int index) { // Allocate a block of 256kb cachable physical memory that will be used to lock the L2 range. BYTE* pPhysMemoryPtr = (BYTE*)XPhysicalAlloc(256 * 1024, MAXULONG_PTR, 256 * 1024, PAGE_READWRITE | MEM_LARGE_PAGES); if (pPhysMemoryPtr == NULL) { DbgPrint("Failed to allocate memory for L2 cache lock\n"); DbgBreakPoint(); VdDisplayFatalError(0x12400 | ERR_LOCKL2_OOM); } // Reserve L2 cache and lock 2 of the available pathways. if (XLockL2(index, pPhysMemoryPtr, 256 * 1024, XLOCKL2_LOCK_SIZE_2_WAYS, 0) == FALSE) { DbgPrint("Failed to reserve L2 cache range\n"); DbgBreakPoint(); VdDisplayFatalError(0x12400 | ERR_LOCKL2_RESERVE); } // Fill the cache with trash data. memset(pPhysMemoryPtr, 0x41, 256 * 1024); // Commit the L2 cache range and prevent it from being replaced. if (XLockL2(index, pPhysMemoryPtr, 256 * 1024, XLOCKL2_LOCK_SIZE_2_WAYS, XLOCKL2_FLAG_SUSPEND_REPLACEMENT ) == FALSE) { DbgPrint("Failed to commmit L2 cache range\n"); DbgBreakPoint(); VdDisplayFatalError(0x12400 | ERR_LOCKL2_COMMIT); } } |
The way this works is we first allocate a block of 256KB of physical memory that will be used to back the L2 lock. Then we reserve a portion of L2 cache that’s the same size as the physical memory allocation and fill it with data. When the CPU sees any reads and writes to this memory region it’ll redirect them to the reserved region of L2 cache. Finally, we commit the lock which prevents that region of L2 cache from being evicted. This function can be used to lock up to 512KB of L2 cache and 4 of the available pathways for an overall reduction of 50% of L2 cache. This will put a lot of pressure on the remaining L2 cache which will cause an increase in cache misses, thus increasing the likelihood of the payload thread fetching the malicious ciphertext from RAM.
After modifying the poc to use the LockAndThrashL2 function I was happy to see the success rate of the race condition had gone from hitting once every 10-15 minutes down to once every 2-3 minutes. This was a huge increase and the L2 thrashing was working great.
Offsetting the Race Timing
The next issue to deal with was the race timing. The race was typically being won during the first half of the decompression process and since we’re targeting the last block of compressed data, I needed to find a way to shift the window of opportunity to the last half of the decompression process. Initially I tried adding a delay between when the attack thread observes the oracle ciphertext and when it starts hammering the LZX decoder structure. However, no matter how much I tweaked the length of the delay I wasn’t able to get anything consistent enough to slide the attack window to the second half of the decompression process. So I decided to take a different approach.
Currently the oracle data (which was 16 bytes of 00s) was based on when the XKE payload did the in-place relocation of the LZX scratch buffer to encrypted memory and zero-initialized it. After the XKE payload initializes this memory it would verify the RSA signature on the compressed input data and decrypt it, before finally calling LDICreateDecompression which would fill the first 16 bytes of the LZX decoder structure with data. This gave a pretty large window of opportunity to observe the ciphertext for the oracle data but led to the attack window happening too early. I decided to change the oracle data to be the first 16 bytes of the LZX decoder structure after it was initialized by LDICreateDecompression, in hopes it would shift the attack window to the latter half of the decompression process.
The first 16 bytes of the LZX decoder structure is just a header with some constant values based on the parameters provided to LDICreateDecompression, so I could easily change the poc to generate the ciphertext for this data. You can see this change in lines 4-6 below:
|
1 2 3 4 5 6 7 |
// Get the cipher text for the expected header data in the LZX decoder context. This acts as our // "oracle" to know when to start the race attack. memset(pMemoryAddress + ScratchOffset, 0, 16); *(ULONG*)(pMemoryAddress + ScratchOffset + 0) = 0x4349444c; // signature = 'CIDL' *(ULONG*)(pMemoryAddress + ScratchOffset + 4) = 0x8000; // windows size = 0x8000 *(ULONG*)(pMemoryAddress + ScratchOffset + 8) = 1; // cpu type = 1 __dcbst(ScratchOffset, pMemoryAddress); |
With the change in place I re-ran the poc a number of times and saw that the attack window had shifted to the latter half of the decompression process, and in some cases was winning the race on the last block of data. The poc was nearing completion, however, it was about this time that a new issue had popped up.
Dirty Cache
When testing the previous change there were a number of iterations where the race was supposedly won on the last block but the console would crash when trying to patch the hypervisor system call table. This could only happen if the block that was written to memory wasn’t the last block in the input file and the data being written over the HvxFlushUserModeTb system call wasn’t our stb/blr instruction sequence.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
DWORD RunUpdatePayloadThreadProc(THREAD_ARGS* pArgs) { ... // Get the cipher text at the location we want to overwrite and at an offset that is > the size of block 14. This allows // us to determine when we win the race on block 14 (smallest block in the file) vs any other block. DWORD* pCipherTextPtr1 = (DWORD*)(0xA0030000 + HV_SEG3_OVERWRITE_OFFSET); DWORD* pCipherTextPtr2 = (DWORD*)(0xA0030000 + (HV_SEG3_OVERWRITE_OFFSET - BLOCK_14_TARGET_OFFSET) + BLOCK_14_SIZE + 0x80); DWORD cipherValue1 = *pCipherTextPtr1; DWORD cipherValue2 = *pCipherTextPtr2; // Loop and hammer the payload until we hopefully get code exec. while (true) { ... // Execute the payload. DWORD result = HvxKeysExecute(pArgs->PayloadPhys, pArgs->PayloadSize, pArgs->UpdateDataPhys, pArgs->UpdateDataSize, NULL, NULL); // Flush cache on the cipher text pointers. __dcbf(0, pCipherTextPtr1); __dcbf(0, pCipherTextPtr2); // Check if we got a block overwrite and if it appears to be block 14. DWORD test1 = *pCipherTextPtr1; if (cipherValue1 != test1) { // We got a block overwrite, check if it was block 14. DWORD test2 = *pCipherTextPtr2; if (cipherValue2 == test2) { DbgPrint("Block 14 overwrite hit!\n"); // Overwrite the syscall function pointer for HvxPostOutput to point to a gadget that will jump to an arbitrary address. DbgPrint(" * Patching hv syscall table\n"); HvWriteULONG(HV_SYSCALL_POST_OUTPUT_ADDRESS, HV_CALL_R4_GADGET_ADDRESS); // Try to execute our shell code which will restore the data we trashed in the last hypervisor segment and patch out // the RSA signature checks on executable files. DbgPrint(" * Running payload\n"); result = HvxPostOutputExploit(0, pArgs->ShellCodePhysAddress); DbgPrint(" * Payload returned 0x%08x\n", result); DbgBreakPoint(); } else { DbgPrint("Race hit: 0x%08x\n", test1); } // Save the latest block hit values. cipherValue1 = test1; cipherValue2 = test2; } } } |
After doing some introspection on my hacked console I was able to confirm that the block being written wasn’t the last block in the input file and that the ciphertext read from the pCipherTextPtr2 pointer was stale. This basically meant that the latter portion of data being written to hypervisor memory was getting stuck in L2 cache and not being committed to RAM where it could be observed from kernel mode. This wasn’t a huge issue, it simply meant I had to find a cache flush primitive I could use to get this data committed to RAM.
Finding a Cache Flush Primitive
Finding a cache flush primitive isn’t too difficult, you mainly need to find a function that will process some data and cause what’s currently in L2 cache to age out. Any hypervisor function that meets the following criteria will work:
- Runs in hypervisor context. Kernel mode cannot flush cache lines that were allocated by hypervisor mode.
- Runs with caching enabled. The hypervisor normally runs with caching disabled so we’ll need to find a function that enables caching before processing the data. Any function that operates on data using the encrypted pathway will do this.
- Touches as much data as possible while also performing as little validation as possible.
After looking through all the hypervisor functions that operate on encrypted memory I came across a system call called HvxRevokeUpdate that met the above criteria. This function is used to encrypt a console certificate revocation list using a per-console key. These revocation lists are used to blacklist console certificates that have been considered “compromised”. For example, if someone hacked their console and used their console certificate to sign malicious game saves (for hacking the console or cheating online), Microsoft could blacklist the console certificate used to sign them by adding it to the revocation list and distributing it over Xbox Live or in system updates. After it’s been revoked any game save signed by that console certificate will show up as “corrupted” and can’t be loaded.
For us this function is a great cache flush primitive because it operates on an input buffer up to 0x20000 bytes large in encrypted memory and performs no validation on the input data. We simply provide it an empty input buffer and once the hypervisor enables caching and touches this data from the encrypted pathway it’ll cause old data in L2 cache to be evicted. After including the cache flush primitive into the exploit poc I ended up with the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
DWORD RunUpdatePayloadThreadProc(THREAD_ARGS* pArgs) { // Allocate a scratch buffer to help with flushing L2 cache in hypervisor context. BYTE* pCacheFlushBuffer = (BYTE*)XPhysicalAlloc(0x20000, MAXULONG_PTR, 0x10000, PAGE_READWRITE | MEM_LARGE_PAGES); if (pCacheFlushBuffer == NULL) { DbgPrint("Failed to allocate memory for cache flush buffer\n"); DbgBreakPoint(); VdDisplayFatalError(0x12400 | ERR_CACHE_FLUSH_BUFFER_OOM); } ULONG CacheFlushBufferPhys = MmGetPhysicalAddress(pCacheFlushBuffer); ... // Loop and hammer the payload until we hopefully get code exec. while (true) { ... // Execute the payload. DWORD result = HvxKeysExecute(pArgs->PayloadPhys, pArgs->PayloadSize, pArgs->UpdateDataPhys, pArgs->UpdateDataSize, NULL, NULL); // Flush cache on the cipher text pointers. __dcbf(0, pCipherTextPtr1); // Check if we got a block overwrite and if it appears to be block 14. DWORD test1 = *pCipherTextPtr1; if (cipherValue1 != test1) { // Flush cache on the secondary cipher text pointer. This one MUST be thorough or else we risk fetching stale data // and trying to execute the post-block-write part of the exploit which will cause the console to hang. HvxRevokeUpdate(CacheFlushBufferPhys, 0x20000, 0); __dcbf(0, pCipherTextPtr2); // We got a block overwrite, check if it was block 14. DWORD test2 = *pCipherTextPtr2; if (cipherValue2 == test2) { DbgPrint("Block 14 overwrite hit!\n"); // Overwrite the syscall function pointer for HvxPostOutput to point to a gadget that will jump to an arbitrary address. DbgPrint(" * Patching hv syscall table\n"); HvWriteULONG(HV_SYSCALL_POST_OUTPUT_ADDRESS, HV_CALL_R4_GADGET_ADDRESS); // Try to execute our shell code which will restore the data we trashed in the last hypervisor segment and patch out // the RSA signature checks on executable files. DbgPrint(" * Running payload\n"); result = HvxPostOutputExploit(0, pArgs->ShellCodePhysAddress); DbgPrint(" * Payload returned 0x%08x\n", result); DbgBreakPoint(); } else { DbgPrint("Race hit: 0x%08x\n", test1); } // Save the latest block hit values. cipherValue1 = test1; cipherValue2 = test2; } } } |
Running the updated poc showed the cache flush primitive was working and the console was no longer crashing on false positives due to stale data in RAM. The only thing left to do now was assemble all the pieces of this exploit into a single chain that I would trigger using my favorite game exploit, Tony Hawk’s Pro Strcpy.
Introducing the Xbox 360 Bad Update Exploit
To turn this into an end-to-end exploit and get hypervisor code execution I’d use my Tony Hawk’s Pro Strcpy bug as an entry point and combine it with the techniques I developed for attacking this bootloader update XKE payload. Putting all of the pieces of the exploit together the full exploit chain would look like so:
- Stage 1
- Stage 2
- Stage 3
- Stage 4
While all the major pieces were already proven to work I still needed to chain them all together into a top-down exploit.
A ROP Chain for the Record Books
The technique I developed for getting arbitrary kernel mode code execution was done in C code that I could deploy and run on my hacked console. This code would need to be recreated in a ROP chain, and while the code itself wasn’t very complex doing it all in ROP wasn’t easy. It took about a week to rewrite the C code in ROP and the final chain consisted of 20-30 unique ROP gadgets and just over 28,000 links in the chain. I wrote many parts of the chain in reusable macros and split it across several source files to simplify the process, but even then the complexity of the chain is quite high.
The Grand Finale
With everything in place there was one last thing to do. If you read my Tony Hawk’s Pro Strcpy blog post you might remember I used a homebrew nyan cat executable to test my exploits. It has since become somewhat of a signature for my exploits and while I had a version of this for the Xbox 360 ready to go, I decided to give it a small upgrade. After copying all the exploit files to a USB stick I booted up Tony Hawk’s American Wasteland, loaded my hacked game save, and waited. I knew from test runs on my hacked console that the exploit had a low success rate (around 35%) and could take upwards of 30 minutes to trigger, but I was ecstatic when it triggered on the first attempt in only a few minutes time. I now had an end-to-end hypervisor exploit that worked on the latest system software (version 17559) and could be triggered using software only methods.
Full source code and files for the exploit can be found on GitHub: Xbox360BadUpdate.
Exploit F.A.Q.
There are a couple questions I know people will be asking about the current state of the exploit, if a softmod is available, and how it compares to things like the RGH hack. I’ve provided answers to a few of these here.
- What Xbox 360 software/kernel version does this exploit work on?
- Does this mean a “softmod” is now available?
- Can this be turned into a softmod/made persistent?
- Why does the exploit take so long to trigger/can it be made faster/more reliable?
- Should I use this instead of the RGH hack?
Conclusion
This exploit took around two and half months to research, develop, and finish but it felt like an eternity. There were many times I thought I hit a dead end and had no path forward, only to spend a day or two thinking and coming up with something new to try. Finding and developing this exploit pushed my abilities as a security researcher, from understanding how the console worked, to finding ways to create attack surface when there otherwise wasn’t any, to using anything and everything I possibly could to help win the race condition and (quite literally) beat the CPU into submission. The constant need to think outside the box and turn nothing into something is part of what I love about being a security researcher, but it’s also exhausting.
Now that I’ve completed this exploit I’m going to retire from game console hacking (at least for the foreseeable future). I’ve learned all I wanted to learn and hacked all I wanted hacked, now it’s time I explore some new avenues. I want to give a big shout out to everyone who encouraged me to continue working on this through all the ups and downs, doom, “x”, and the Seabards for listening to all my rambling about L2 cache fuckery and the numerous times I thought I hit a dead end. Once again, a big thank you to everyone who read through this wall of text. Even though it’s quite long this blog post doesn’t even begin to capture all the work that made this exploit possible.
For anyone who wants to read more about the Xbox 360 inner workings I plan to write a part 3 where I’ll (briefly) cover some of my failed attempts at exploiting the console, and other interesting behavior/techniques I developed along the way. However, this part won’t be written for several months time so don’t count on it any time soon.

Amazing work 🙂
Also appreciate the titles of various sections of these posts. You have good taste in music 🤣
Thank you very much for sharing your adventure! As embedded developer, this was great read. Fantastic job.
I’m glad you shit on every hater/doubter.
Bravo. You have stunned the community and shook your haters and doubters.
Thank you, So interesting and inspiring and glad you have beaten the “final boss”
Well written and although I probably won’t ever understand it all I will enjoy trying
Awesome work! Love that in the end the hypervisor still remains impenetrable. That pesky trusted XKE however stood no chance.
Wouldn’t the modern day shader equivalent not be a mesh shader as opposed to a vertex shader? Tbh, I don’t know much about mesh shaders but from how it is described here it sounds like it.
Ah yes, that’s a typo on my part.
*as opposed to a fragment shader
“which are similar to modern day fragment shaders. These shaders allow the GPU to write back to RAM to create vertex, index, or texture buffers dynamically.”
Wouldn’t something like that then be a mesh shader?
Congrats!
(For a split second I was worried that it would have been any of the Hvx challenges, but no, it wasn’t my fault.)
Thanks! There is a challenge that has some interesting behavior that I tried to exploit at one point. But it requires some hypervisor data in a very specific pattern that I wasn’t able to find any instances of in the wild.
It worked about 5x and now it doesn’t want to work anymore
Xbox 360 FAT (JASPER)
I love that you defeated this awesomely complex system using basically the same approach we take to making awesomely complex systems: one primitive at a time. Confucius would be proud of this moved mountain 😉
Congrats on this amazing writeup and exploit chain. Absolute god tier work and very impressive. Such a joy to read. Have some coffees on my behalf and have a wonderful day. 🙂
Amazing work! Thanks for the detailed write-up.
Do you have plans to “optimize” times or rate of success?
Eu li tudo, parte 1 e parte 2, obrigado pelo seu trabalho incrível.
The more I read this, the more I’m impressed about the amount of work and dedication used to get this done
The only thing I can see to make this even more consistent is getting that wait time down to mere minutes, and then finding a way to get the exploit embedded to the Hypervisor’s code so the exploit can be booted up on launch via a button or just be active on launch
I personally don’t mind rerunning the exploit each time on boot atm. I have a hacked Wii U since the Browser exploit was created. That was a non-persistent exploit until they found a way to change a DS Virtual Console game to the Homebrew Launcher, and embed the CFW to the nand so it can boot up on launch
Most interesting write-up I’ve ever read. And you are truly a king at reverse engineering and thinking of pathways extremely few people can.
It is also interesting that you can write so detailed about the progress, you must have taken notes most of the way. I bow to you Sir.
Thanks for the article and the emormous amount of work you put into this ❤
You said: “The exploit works on all software versions up to/through 17559, although there is some version-specific information that would need to be updated for any version other than 17559.”
Which ones? I have an Xbox that won’t update, so knowing this, I try to adapt.